System Design
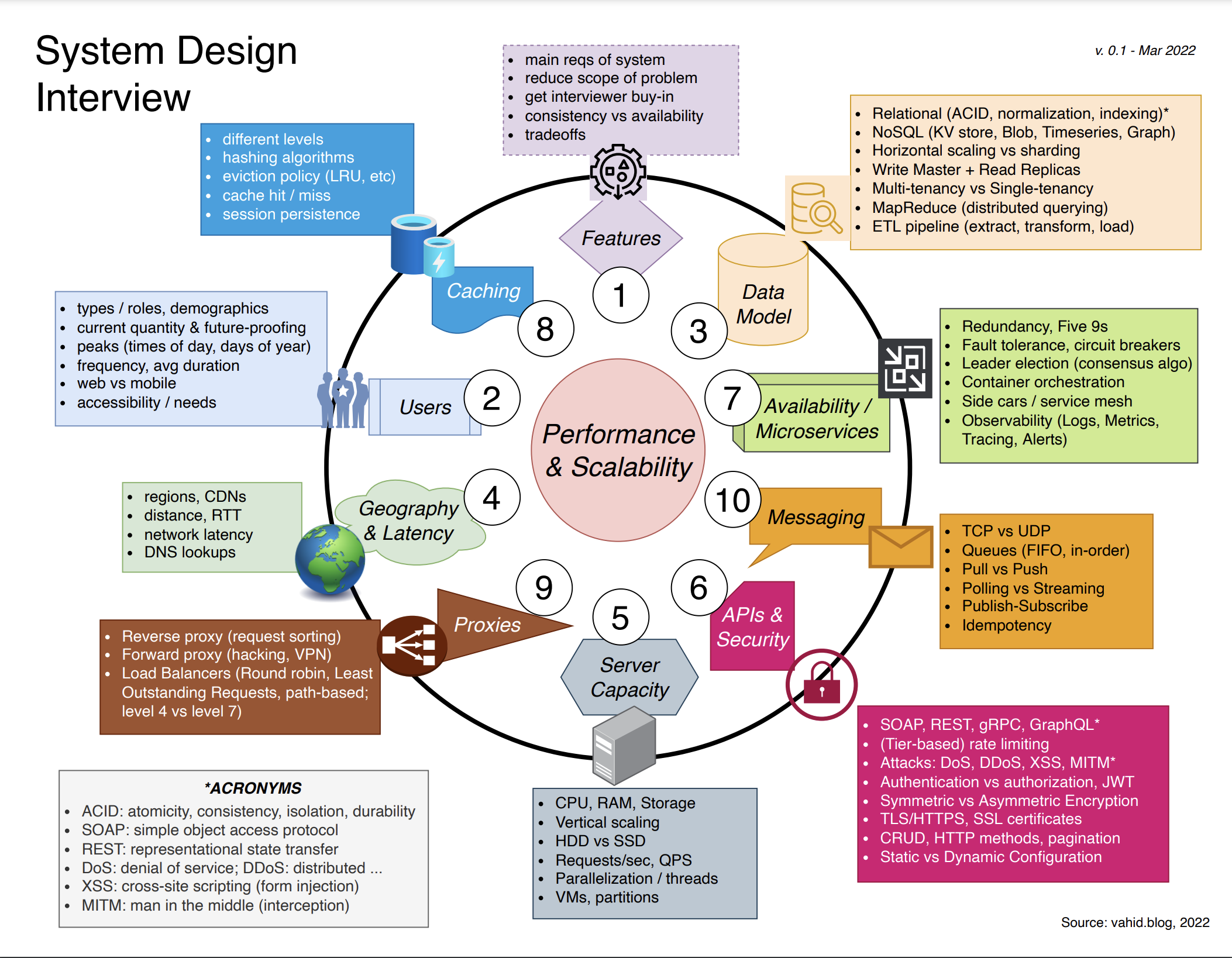
Early Considerations
Define scope
- Describe the potential surface area of the application, listing out features. Anything is on the table
- Constrain the scope with the interviewer
- What domain primitives do we have?
Back-of-the-envelope
- How much main domain data are we storing?
- ex. if Spotify, how many songs are we storing? If Facebook, how many posts are we storing?
- How many users?
User traffic patterns
- How many daily active users (DAU)?
- How many concurrent users anticipated?
How does the typical user use our application?
- Sequential Access Pattern - Users follow a sequential or linear path through the application or website.
- ex. in a step-by-step registration process or an e-commerce checkout flow, users move from one page to the next in a predefined sequence.
- Random Access Pattern - Users access different pages or features of the application in a non-linear, unpredictable manner. They commonly arrive directly from search engine results, bookmarks, or external links.
- ex. Wikipedia
- Bursty Traffic Pattern - Occasional spikes in traffic or usage, typically caused by specific events, promotions, or viral content.
- ex. Ticketmaster pre-sales
- Daily/Weekly/Seasonal Traffic Pattern - Consistent variations in user traffic based on specific days of the week or times of day.
- ex. e-commerce platforms experience higher traffic during holiday seasons.
- Recurring Traffic Pattern - Users return to the same pages or features regularly
- ex. daily news readers or social media platforms.
Rough high-level component design
Once we have all high-level components in place, run through a use-case
- ex. in Spotify, when a user plays a song, the selected songId is sent from the client to the application server, which sends a query to the relational database to get the song record. Included in the song record is the URL where the
.mp3is stored in the blob storage database...
Database
- SQL or NoSQL?
- Rough table design
Fault tolerance
- deploy.distributed.CAP-theorem (Private): should availability or consistency be prioritized?
- automatic leader promotion on failure
- RDBMS provides a WAL for improved fault-tolerance
Scaling
- Microservice architecture for independent scaling of nodes
- Offload non-critical tasks to a job-queue (implemented with something like Redis streams or Apache Kafka)
- what is the
read:writeratio?
Database
Main app
Write-heavy databases
Consider how read-heavy the data in your application is. Write heavy dbs may face scalability issues.
- For instance, maybe 5x more people are uploading data than are downloading it (a 1:5 read:write ratio). Let's assume 1M writes per day, giving us 5M reads
Things to consider
- Does read data need to be consistent with what was just written? If not, we can cache.
- Efficient indexing (recall that indexes slow down write operations)
- query optimization necessary
- Batching write queries to reduce overhead of establishing connections, executing queries and committing transactions.
- offload write operations to an asynchronous processing mechanism (e.g. queue)
- implement replication and sharding to distribute writes across multiple replicas
If using counters (likes, votes etc.), use distributed counters to distribute load
Can implement caching mechanisms using Redis to reduce load on database
Read-heavy databases
Things to consider
- Implement efficient indexing on read-heavy sets of data
- Identify the most frequently executed queries and create indexes on the relevant columns to support them.
- Implement caching mechanisms
- Use replication to distribute load over multiple replicas
- Use load balancing to distribute load over multiple application servers
- Consider denormalization to reduce amount of joins needed
- Query optimization
Scaling the DB
- Implement read replicas
- Vertically scaling the database to upgrade CPU, RAM and storage
- Sharding (ie. horizontal scaling) the database can help distribute the load
Storage
- Consider moving a certain subset of the data to cold storage to save on costs
Authentication
- Handling large number of registrations and logins will put strain on auth service
- Consider holding a separate database for our auth service, which will issue JWTs to autenticated users, and will verify JWTs.
Static content
- serving static content and handling increased traffic will put a strain on the server and affect the user experience.
- leverage a CDN to offload static asset serving and improve load times.
Cache
- Managing cache validation and ensuring consistency of content across distributed servers can present challenges
- Implement cache versioning and cache invalidation strategies (e.g., using cache headers or file hashing) to maintain consistency.
- We can cache some of the hot data points that are frequently accessed. Following the 80-20 rule, (20% of hot data points generate 80% of traffic), we would like to cache these 20% data points.
- ex. if designing a paste-bin clone, cache the top 20% of most accessed pastes.
Application Server(s)
- if there is concurrently high number of writes to database, make use of message queue like Kafka to decouple the write (eg. Reddit post submission) from the main application
Scaling and High Availability
- Scaling the system and maintaining high availability across multiple regions can be complex.
- Employ horizontal scaling by adding more servers and use load balancers to distribute the load.
- Implement an automated monitoring and alerting system to help identify and address issues
- Employ failover mechanisms to automatically switch to backup systems in case of failure.
- Coordinating data replication and ensuring consistency during updates are challenges.
- Techniques like database replication, data partitioning, and distributed caching can enhance availability and scalability.
Capacity Estimation and Constraints
Can users upload as much as they want? For instance, if we were building Instagram, we would want to make efficient storage of photos a top priority.
Leveraging User Expectations
Have a good understanding of user expectations while designing the application. For instance, in an Instagram-clone, it's not necessary that every user sees the latest content at any given time— we can tolerate some delay. This enables us to retract our focus from strict caching and replication implementations, and instead focus on things that are more important for our system.
How fast do writes need to be? How about reads?
- For Instagram, fast uploads would not be expected by users. Reads, on the other hand would be expected, since there is a high degree of swiping going on. For this, we'd want to have a more sophisticated caching system in place.
- We should keep in mind that web servers have a connection limit before designing our system. If we assume that a single web server instance can have a maximum of 500 connections at any time, then it can’t have more than 500 concurrent uploads or reads to that server. To handle this bottleneck, we can split reads and writes into separate services. We can have dedicated servers for reads and different servers for writes to ensure that uploads don’t hog the system. This has the added benefit of being able to scale each set of services independently.
- If users can upload a large amount of data, then efficient management of storage should also be a focus
How reliable is your app expected to be?
- if you are Instagram, your users expect 100% reliability. Therefore, you should store multiple copies of each file so that if one storage server dies, the photo can be retrieved from the other copy present on a different storage server.
- If we want to have high availability of the system, we need to have multiple replicas of services running in the system so that even if a few services die down, the system remains available and running. Redundancy removes the single point of failure in the system.
Redundancy
All potential bottlenecks and points of failure should be scrutinized. Think of how the system gets more complex as we implement [sharding|db.strategies.sharding]. Now we need a sharding rule to determine in which shard a row is stored. Suppose we implement round robin with recordId % 10 to spread out the records evenly. Well, now we have a new problem: we cannot have the shards increment the IDs themselves, since we need the ID first before we can even determine which shard it belongs in. So to solve that, we need some sort of external key generating service. This service can generate IDs, store them in a table (to indicate that it is used) when a new item is created. Each shard can use this service, and we can have perfectly incremented IDs across all shards. However, one last issue arises. This key generation system is now a single point of failure, so we have to iterate further. We could spin up another such key generating service, and split the load between them by having one service give out even-numbered IDs and the other odd-numbered IDs. Finally, we can stick a load balancer in front of them to round-robin the load between them. In case of failure of the even-numbered service, the only consequence is that there will be more odd-numbered IDs; something we probably don't even care about.
Back-of-the-envelope Estimations
From there, assume that each item is 10KB, so we need to store 10GB per day. If we want to store this data for an average of 10 years then we need storage capacity of 36TB.
- To keep some margin, we will assume a 70% capacity model (meaning we don’t want to use more than 70% of our total storage capacity at any point), which raises our storage needs to 51.4TB.
New items per second:
- 1M / (24 hours * 3600 seconds) ~= 12 pastes/sec results in 120KB of ingress per second.
- 12 * 10KB => 120 KB/s
Reads per second:
- 5M / (24 hours * 3600 seconds) ~= 58 reads/sec results in total data egress (sent to users) will be 0.6 MB/s.
- 58 * 10KB => 0.6 MB/s
This number of records totals 3.6 Billion in 10 years. Since 6 random base64 encoding (Private) ([A-Z, a-z, 0-9, ., -]) can be used to generate 68.7 billion unique strings, this should be sufficient for uniqueness.
Since we have 5M read requests per day, to cache 20% of these requests, we would need:
- 0.2 5M 10KB ~= 10 GB
Dendron notes to review
E Resources
Resources
- System Design Primer
- Distributed counter design
- Real-time presence design
- Live comment system design
- Leaderboard system design
- Pastebin system design
- URL shortening system design
- Service Discovery
- Various system designs
- System Design and Architecture
- System design cheatsheet
- Youtube series: System Design